Decision Trees
Overview
Decision trees allow you to express complicated logic as simple flow charts. Like decision tables, they are another way to decouple decisioning logic from application code and make them accessible to non-technical users.
Evaluate a Simple Decision Tree
This standalone example demonstrates the same logic as the previous decision table – a simple loan eligibility check that can be added to any app. It contains three input fields (Age, House Owned, and Income) and one output field (Eligible).
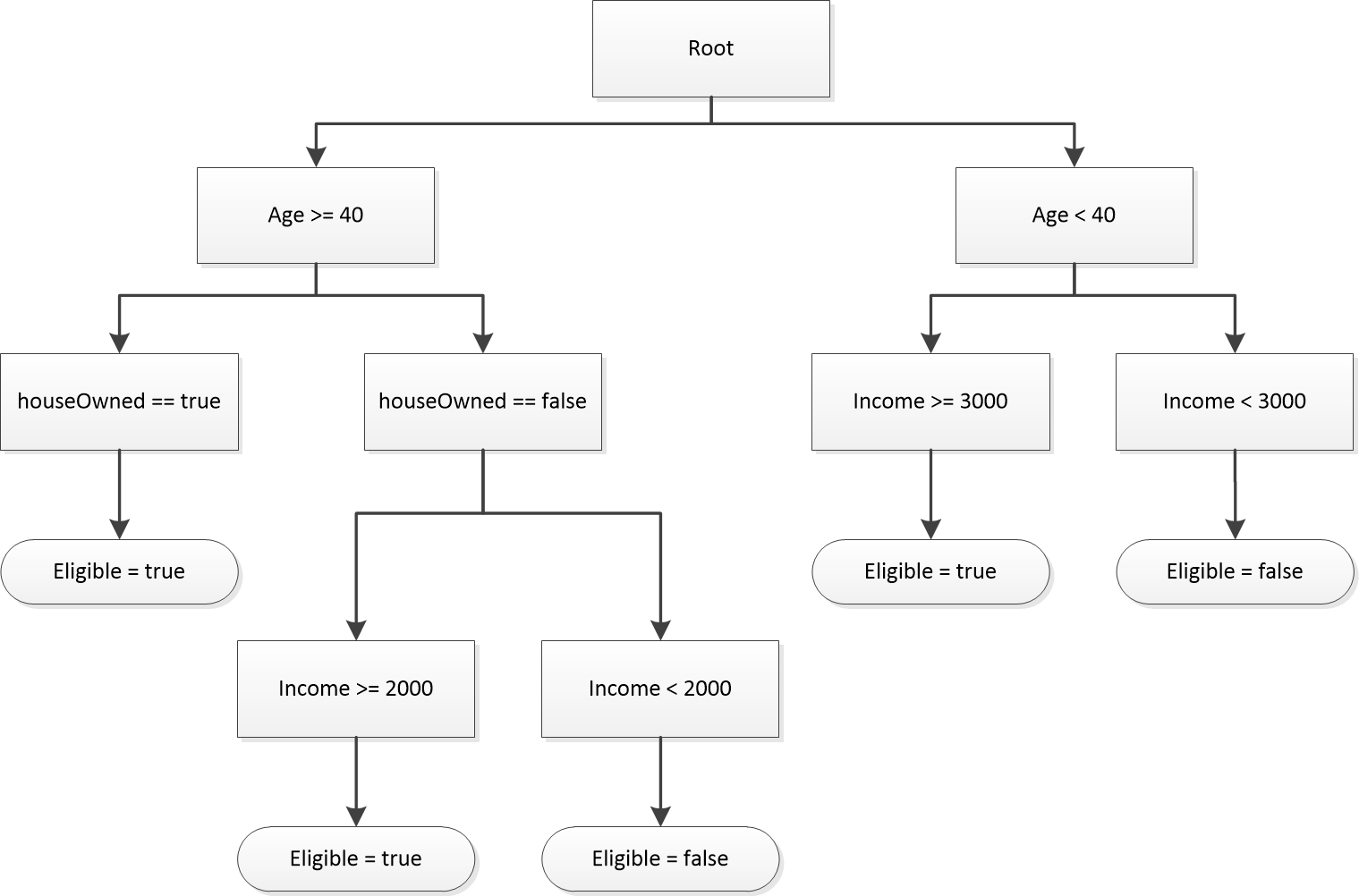
Each node represents a separate rule with a condition and an optional set of outcomes. Rules are evaluated sequentially, in the order they were added, and following along the path where all conditions evaluate to true. Evaluation continues until a terminal node is reached – one without any child nodes that evaluate to true. Processing stops at that point and the outcome fields are evaluated and returned. The outcome fields are collected from all "true" nodes along the path (not just the final node).
A few things to keep in mind:
- Both the condition and outcome cells are specified using the DataPipeline Expression Language.
- Field names containing spaces or symbols must be surrounded by ${}. For example, "House Owned" would have to be wrapped: ${House Owned}.
- Any node can contain an outcome, even if it's not a terminal node. This allows outcomes to be built up along the path of "true" nodes.
- A node can contain multiple outcome fields.
Example: EvaluateADecisionTree.java
Add a Calculated Field to a Decision Tree
Decision trees allow you to replace repeating values and expressions throughout with a single, shared value or expression. This example shows how to add constants (ageThreshold) and expressions (overAgeThreshold) for use in conditions and outcomes.
Example: AddCalculatedFieldsToADecisionTree.java
Evaluate a Decision Tree in a DataPipeline Job
Decision trees are very useful on their own, but they can also be added to any DataPipeline job. This example shows how to add a decision tree to a job that reads a CSV file. It also shows how to:
- Add multiple outcome fields (Total and Product Type).
- Turn outcome fields into calculated expressions (${Variant Price} + Shipping).
- Add calculated fields for use throughout a decision table (Variant Price).
Example: AddADecisionTreeToAPipeline.java
Add a Lookup to a Decision Tree
Decision trees can also use the lookup functions in the expression language to map one value to another from a database, file, or API. This example uses a programmatic lookup to find currency names for their codes in the outcome expression of decision tree nodes.
Example: EvaluateADecisionTreeWithLookup.java
Run an Action when a Decision Tree Node is Reached
Sometimes the outcome of a decision node should be an action. This example shows how to call an arbitrary function when a node is true.
Here are a few things to keep in mind:
- The example contains two static functions:
action1()andaction2(int age, double income). - A simple
action2alias is created for the second function, otherwise, it's fully-qualified name would have to be used. - Outcomes always require a field name, even if their expression calls a void function.
- Input fields can be used in the outcome and passed to user-defined functions.
Example: ExecuteAnActionInADecisionTree.java
Save a Decision Tree to/from XML
This example saves a programmatically built decision tree to XML and loads it back. This allows you to store decision trees as program resources on disk or in a database. It also allows you to modify them programmatically and save them back to disk.
Example: SaveAndLoadDecisionTreeToXML.java
The generated XML for the above decision tree would be the following.
Expression Language Built-In Variables
| Variable | Description | Example |
|---|---|---|
| rownum | The current row number, starting at 1. | rownum % 2 == 0 |