What is Data Pipeline
Overview
Data Pipeline is an embedded data processing engine for the Java Virtual Machine (JVM). The engine runs inside your applications, APIs, and jobs to filter, transform, and migrate data on-the-fly.

Data Pipeline speeds up your development by providing an easy to use framework for working with batch and streaming data inside your apps.

The framework has built-in readers and writers for a variety of data sources and formats, as well as stream operators to transform data in-flight.
What you can do with Data Pipeline
Here are a few things you can do with Data Pipeline.
- Convert incoming data to a common format.
- Prepare data for analysis and visualization.
- Migrate between databases.
- Share data processing logic across web apps, batch jobs, and APIs.
- Power your data ingestion and integration tools.
- Consume large XML, CSV, and fixed-width files.
- Replace batch jobs with real-time data.
Common Data API
Data Pipeline provides you with a single API for working with data. The API treats all data the same regardless of their source, target, format, or structure.
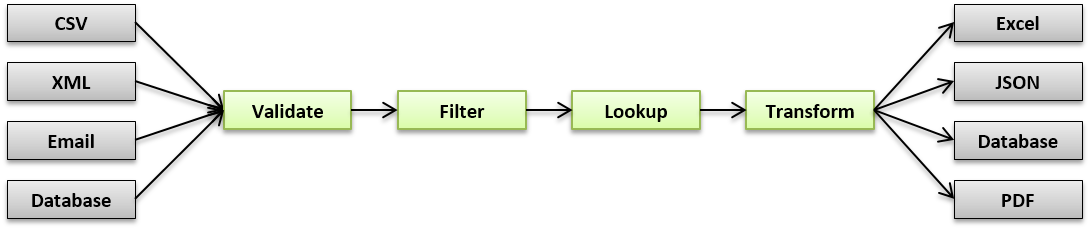
By developing your applications against a single API, you can use the same components to process data regardless of whether they're coming from a database, Excel file, or 3rd-party API. You're also future-proofed when new formats are introduced.
A common API means your team only has one thing to learn, it means shorter development time, and faster time-to-market. It also means less code to create, less code to test, and less code to maintain.
Flexible Schema
Data Pipeline does not impose a particular structure on your data.
Records can contain tabular data where each row has the same schema and each field has a single value.
Records can also contain hierarchical data where each node can have multiple child nodes and nodes can contain single values, array values, or other records.

Each piece of data flowing through your pipelines can follow the same schema or can follow a NoSQL approach where each one can have a different structure which can be changed at any point in your pipeline.
This flexibility saves you time and code in a couple ways:
- In many cases, you won't need to explicitly refer to fields unless they are being modified. For example, if your customer's account numbers flows through your pipelines without being transformed, you generally don't need to specify it. Data Pipeline will automatically pick it up from the data source and send it along to the destination for you.
- If new fields are added to your data source, Data Pipeline can automatically pick them up and send them along for you. No need to recode, retest, or redeploy your software.
Metadata
Data Pipeline allows you to associate metadata to each individual record or field. Metadata can be any arbitrary information you like. For example, you can use it to track where the data came from, who created it, what changes were made to it, and who's allowed to see it. You can also use it to tag your data or add special processing instructions.
Process Large Volumes of Data in Real-time
Data Pipeline views all data as streaming. Regardless of whether the data is coming from a local Excel file, a remote database, or an online service like Twitter. By breaking dataflows into smaller units, you're able to work with datasets that are orders of magnitude larger than your available memory. Streaming data in one piece at a time also allows you to process data immediately — as it's available, instead of waiting for data to be batched or staged overnight.
Embed Inside Your Apps
Data Pipeline fits well within your applications and services. It has a very small footprint, taking up less than 20 MB on disk and in RAM. It's also complication free — requiring no servers, installation, or config files. You just drop it into your app and start using it.
In-flight Processing
Data Pipeline runs completely in-memory. In most cases, there's no need to store intermediate results in temporary databases or files on disk. Processing data in-memory, while it moves through the pipeline, can be more than 100 times faster than storing it to disk to query or process later.
Flexible Data Components
Data Pipeline comes with built-in readers and writers to stream data into (or out of) the pipeline. It also comes with stream operators for working with data once it's in the pipeline. You can save time by leveraging the built-in components or extend them to create your own reusable components containing your custom logic.
Easy to Use
Data Pipeline is very easy to learn and use. Its concepts are very similar to the standard java.io package used by every developer to read and write files. It also implements the well-known Decorator Pattern as a way of chaining together simple operations to perform complex tasks in an efficient way. Developers with experience working on the command line in Linux/Unix, Mac, or DOS/Windows, will be very familiar with concept of piping data from one process to another to form a processing pipeline.
100% Java
Data Pipeline is built on the Java Virtual Machine (JVM). You write pipelines and transformations in Java or any of the other JVM languages you know (Scala, JavaScript, Clojure, Groovy, JRuby, Jython, and more). You can also use your existing tools, IDEs, containers, and libraries. Being built on the JVM means it can run on all servers, operating systems, and environments.