Declarative Pipelines
Overview
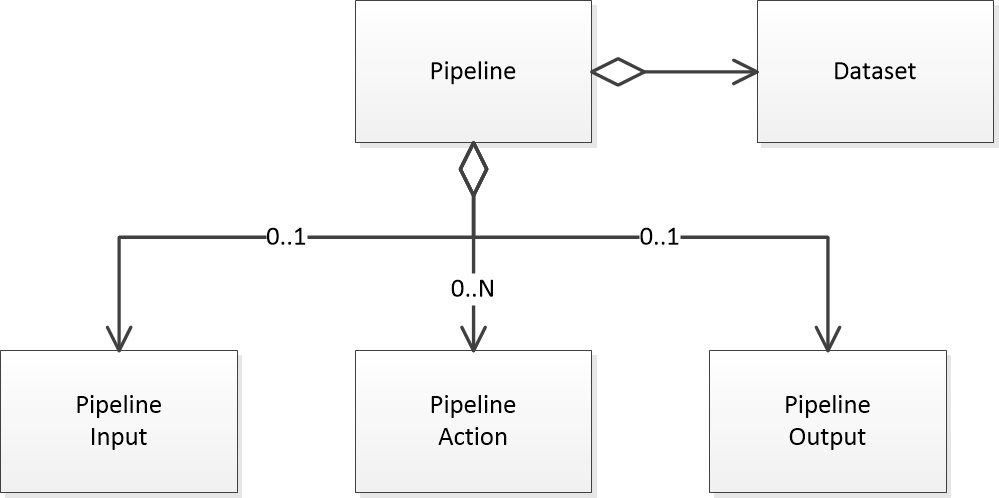
Pipelines are a new way to create your DataPipeline jobs. Instead of working directly with readers and writers, pipelines allow you to create jobs declaratively with inputs, outputs, actions, and datasets. Pipelines are built on the core DataPipeline engine and are used in the online data prep tool.
Create and run a Declarative Pipeline
This example shows how to build a pipeline that reads a local CSV file, applies three actions (rename, convert, add field), and writes to an Excel file.
Example: ReadFromCsvWriteToExcel.java
Save and load Pipeline from JSON
The Pipeline class includes methods to convert itself to and from a DataPipeline Record. This allows you load and store pipelines to XML and JSON using the record's built-in methods.
This example creates a pipeline with several actions, saves it to JSON, loads it back from the record, and then runs it. The toJsonString() and fromJsonString() that rely on the toRecord() and fromRecord() methods.
Example: SaveAndRestorePipelineFromJson.java
The generated JSON for the above pipeline would be the following.
Pipeline Examples
In addition to providing a simple declarative structure, pipelines contain other features you may find useful.
Show Column Statistics
Pipelines allow you to obtain data, metadata, and statistics for each column. This information is retrieved after all actions are applied to the data coming from the pipeline's input.
The first step is to instantiate a dataset.
Dataset dataset = new MemoryDataset(pipeline);Next, you start the asynchronous data loader. This is a non-blocking call and will run in parallel, behind the scenes. You have the option of loading all data or a maximum number of recods.
dataset.load();You then have the option to wait for all data to be loaded, for a maximum period of time, or for a minimum amount of records.
dataset.waitForRecordsToLoad();Once your full or partial snapshot is loaded, you can then retrieve the columns and inspect their values.
dataset.getColumns()This example shows how to retrieve the statistics for each column in a CSV file.
Example: ShowColumnStatistics.java
Show Unique Values in Column
The dataset in a pipeline also contains a histogram of the unique values in each column. This can aid in analyzing your data or determine which actions to add next in the pipeline.
This example shows how to obtain the list of unique values for each column in a CSV file along with their counts.
Example: ShowUniqueValuesInColumn.java
Load Snapshot of Dataset
Pipelines provide easy access to the data they load as well as flexibility in how much data is loaded and how long you wait while it's loading.
This example shows how to load all data from a file, but only wait for the first 10000 records or 4 seconds — whichever comes first — before proceeding. The remaining data will continue to load in the background.
Example: LoadSnapshotOfDataset.java
Filter Columns With All Null Values
Some data you'll work with may have optional columns that contain null values when not in use.
This example shows how to use column statistics to build a dynamic pipeline that filters out unused columns. The pipeline converts a CSV file to Excel and removes unused columns – those containing only null values.
Example: FilterColumnsWithAllNullValues.java