
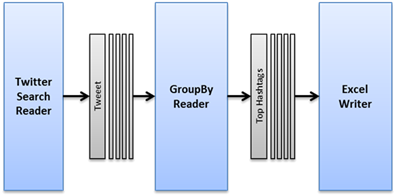
One feature of Data Pipeline is its ability to aggregate data without a database. This feature allows you to apply SQL “group by” operations to JSON, CSV, XML, Java beans, and other formats on-the-fly — in real-time. This quick tutorial will show you how to use the GroupByReader class to aggregate Twitter search results.
Demo — Export Twitter Searches to Excel
We used the code in this post to create a Twitter search tool at https://birdiq.net/twitter-search.
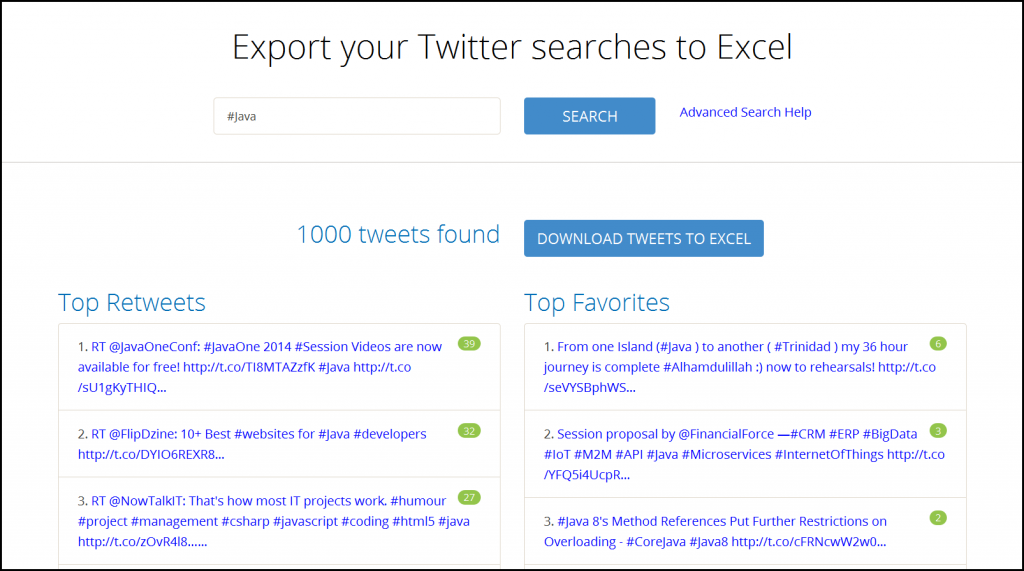
This demo summarizes up to 1000 tweets matching your search query to find the top:
- Retweets
- Favorites
- Hashtags
- Mentions
- URLs
- Users
The search results page shows the top 10 items for each of the above, while the Excel spreadsheet contains the summary plus all of the original tweets.
Since this is only a demo, we run searches one-at-a-time and limit the results to 1000 tweets.
Step 1: Search for tweets
The first step is to setup a data source. In this case, you can start a Twitter search using TwitterSearchReader. You’ll need a consumer key and secret from https://apps.twitter.com/ to access Twitter’s APIs. You’ll also need to pass in a search query and the maximum number of tweets to return — #Java and 1000 in this example.
|
1 2 3 |
DataReader reader = new TwitterSearchReader(CONSUMER_KEY, CONSUMER_SECRET, "#Java", MAX_RESULTS) .setApiLimitPolicy(ApiLimitPolicy.STOP) .setEntityExpansionPolicy(EntityExpansionPolicy.TO_ARRAY); |
API Limit Policy
Twitter sets limits on how many API calls you can make every 15 minutes. The ApiLimitPolicy.STOP enum tells Data Pipeline to stop the DataReader normally — as if there’s no more data — if the Twitter API call limit is reached. Other options are to FAIL by throwing an exception or WAIT up to 15 minutes for the limit to be reset. You can also create your own policy by implementing IApiLimitPolicy.
Entity Expansion Policy
Some twitter fields like hashtags, mentions and URLs can contain multiple values. The EntityExpansionPolicy.TO_ARRAY enum tells Data Pipeline to return these multi-valued fields as an array field. You can also use TO_STRING to return it as a single, space-separated string or you can create your own policy by implementing IEntityExpansionPolicy.
Caching Tweets Temporarily
|
1 2 3 |
RecordList tweets = new RecordList(); DataWriter writer = new MemoryWriter(tweets); JobTemplate.DEFAULT.transfer(reader, writer); |
Normally you would stream data through your pipeline to keep memory low and process data quickly. For this example, we’ll temporarily save the tweets in a RecordList. This will allow you to cache them in something like Ehcache in order to handle the same search query in a short period of time. In the above demo, we use caching to prevent calling the Twitter API a second time when the Excel download link is clicked.
Step 2: Save the tweets to Excel
Now that you have the tweets in memory, the first thing you need to do is add them to an Excel tab named “tweets”.
|
1 2 3 4 5 6 7 |
reader = new MemoryReader(tweets); ExcelDocument document = new ExcelDocument(); writer = new ExcelWriter(document) .setSheetName("tweets") .setAutofitColumns(true) .setAutoFilterColumns(true); JobTemplate.DEFAULT.transfer(reader, writer); |
The setAutofitColumns() call expands the columns widths to fit the widest value. The setAutoFilterColumns() call adds a row above the data with a drop-down to filter the spreadsheet using the values from each column. At this point the ExcelDocument is stored in memory and will be saved to disk later on.
Step 3: Group and count hashtags, mentions, URLs, and retweets
The next step is summarize the saved tweets to find the top hashtags, users, etc. This will take the form of two reusable methods: top() and count().
Top Tweets
In some cases, Twitter already provides summary data with every tweet. For example, each tweet has a field for the number of times it was retweeted and another for the number of times someone marked it as their favorite. If a tweet gets retweeted 5 times, you might see 6 tweets in the search results — the original tweet, plus the retweets. For these cases, you need to “group by” the text of the tweets to remove duplicates and grab the highest (max) value from the summary field. You’ll also grab the first value for the other fields you need in the output.
Once the data is grouped and summarized, you’ll sort the data by the summary and text field, take the top n records, and select the fields you want to retain in the output, in the arrangement you want to see them.
This reusable method takes the following parameters:
- tweets – the cached tweets
- document – the target Excel document
- topCount – the number of top rows to return
- topField – the summary field containing the counts
- firstFields – the other fields to return in the output sent to the Excel document
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
private static void top(RecordList tweets, ExcelDocument document, int topCount, String topField, String ... firstFields) { DataReader reader = new MemoryReader(tweets); GroupByReader groupByReader = new GroupByReader(reader, "Text") .setExcludeNulls(true) .max(topField, topField, true); if (firstFields != null) { for (String firstField : firstFields) { groupByReader.first(firstField, firstField, false); } } reader = groupByReader; reader = new SortingReader(reader).desc(topField).asc("Text"); reader = new LimitReader(reader, topCount); reader = new TransformingReader(reader) .add(new SelectFields().add(topField).add("Text").add(firstFields)); DataWriter writer = new ExcelWriter(document) .setSheetName(topField) .setAutofitColumns(true) .setAutoFilterColumns(firstFields != null && firstFields.length > 0); JobTemplate.DEFAULT.transfer(reader, writer); } |
Count Tweets
In other cases, Twitter doesn’t provide summary counts and you’ll need to group and count the values yourself. For example, you’ll need to group and count all the hashtags and URLs found in each tweet.
This reusable method takes the following parameters:
- tweets – the cached tweets
- document – the target Excel document
- countField – the field containing the values to group-by and count
- firstFields – the other fields to return in the output added to the Excel document
Unlike many SQL databases, the fields you’re going to use in the “group by” may contain array values. For example, the HashtagEntities field could contain #Java, #WebDevelopment, and #SpringFramework. When GroupByReader receives array values, it treats each value in the array separately, as if it was the only value in that record’s field. This allows it to group and count all the #Java hashtags on their own.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
private static void count(RecordList tweets, ExcelDocument document, String countField, String ... firstFields) { DataReader reader = new MemoryReader(tweets); reader = new TransformingReader(reader).add(new BasicFieldTransformer(countField).lowerCase()); GroupByReader groupByReader = new GroupByReader(reader, countField) .setExcludeNulls(true) .count("count", true); if (firstFields != null) { for (String firstField : firstFields) { groupByReader.first(firstField, firstField, false); } } reader = groupByReader; reader = new SortingReader(reader).desc("count").asc(countField); DataWriter writer = new ExcelWriter(document) .setSheetName(countField) .setAutofitColumns(true) .setAutoFilterColumns(firstFields != null && firstFields.length > 0); JobTemplate.DEFAULT.transfer(reader, writer); } |
Summarize Tweets
You can now call the above methods to add the summary tabs to the Excel document.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
count(tweets, document, "HashtagEntities"); count(tweets, document, "UserMentionEntities"); count(tweets, document, "URLEntities"); count(tweets, document, "UserScreenName", "UserFollowersCount", "UserFollowingCount", "UserTweets", "UserFavouritesCount", "UserLocation", "UserLang", "UserTimeZone", "UserUtcOffset", "UserCreatedAt", "UserURL", "UserDescription"); top(tweets, document, 10, "RetweetCount", "FavoriteCount", "Id", "Text", "HashtagEntities", "UserMentionEntities", "URLEntities", "UserScreenName", "UserFollowersCount", "UserFollowingCount", "UserTweets", "UserFavouritesCount", "UserLocation", "UserURL", "UserDescription"); top(tweets, document, 10, "FavoriteCount", "RetweetCount", "Id", "Text", "HashtagEntities", "UserMentionEntities", "URLEntities", "UserScreenName", "UserFollowersCount", "UserFollowingCount", "UserTweets", "UserFavouritesCount", "UserLocation", "UserURL", "UserDescription"); |
Step 4: Save the Excel spreadsheet to disk
The final step is to take the ExcelDocument and save it to disk (or HTTP response stream like in the demo’s case).
|
1 |
document.save(new File("twitter.xlsx")); |
That’s all there is to it. You now have an Excel document containing a tab with the original tweets, plus several other tabs containing summary data.
Twitter Streaming
As we promised at the start, you were able to aggregate data in your own app without setting up a database to store and query the tweets or running a separate data processing server. Of course, you can always write the results to a database at any time.
Next time we’ll show you how to continuously aggregate data from Twitter’s streaming API in real-time — again without using a database.
Happy Coding!
Pingback: Aggregate data in Java without a database | JAVA