
Today we’re pleased announce the release of Data Pipeline version 4.4. This update includes integration with Amazon S3, new features to better handle real-time data and aggregation, and new XML and JSON readers to speed up your development.
Today we’re pleased announce the release of Data Pipeline version 4.4. This update includes integration with Amazon S3, new features to better handle real-time data and aggregation, and new XML and JSON readers to speed up your development.
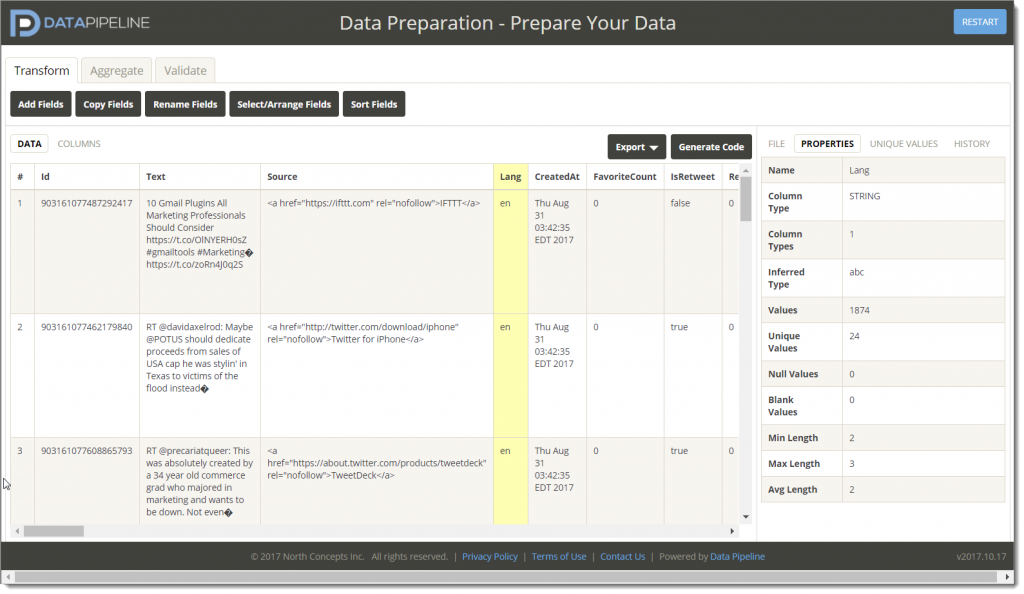
We’re building on a new tool to help you work faster with Data Pipeline.
This new tool is a web app that lets you interactively transform, filter, and prepare data on-the-fly. It also lets you generate Data Pipeline code based on the actions you perform.
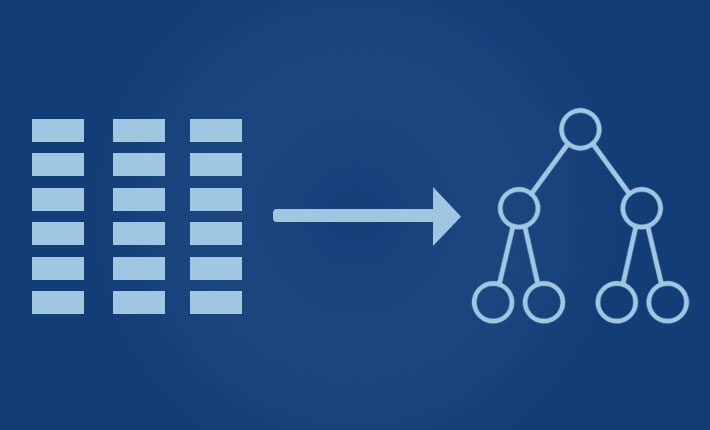
We recently received an email from a Java developer asking how to convert records in a table (like you get in a relational database, CSV, or Excel file) to a composite tree structure. Normally, we’d point to one of Data Pipeline’s XML or JSON data writers, but for good reasons those options didn’t apply here. The developer emailing us needed the hierarchical structures in object form for use in his API calls.
Since we didn’t have a general purpose, table-tree mapper, we built one. We looked at several options, but ultimately decided to add a new operator to the GroupByReader. This not only answered the immediate mapping question, but also allowed him to use the new operator with sliding window aggregation if the need ever arose.
The rest of this blog will walk you through the implementation in case you ever need to add your own custom aggregate operator to Data Pipeline.

Earlier this year a friend sent me a video showing how he implemented a phone bill calculation challenge using Scala. I took a stab at it using Java + Data Pipeline and below is what I came up with.
How about you? How would you code this using your favourite language or framework?
Updated: July 2021
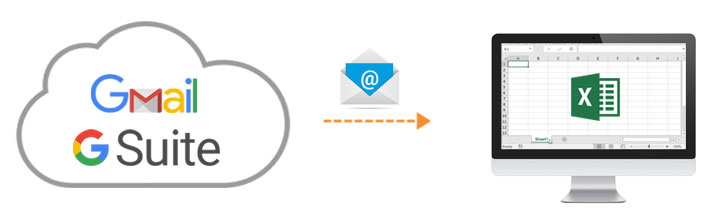
If you have ever tried to export emails to Excel for analysis, you know it is not exactly straightforward. Maybe you need to find the top companies contacting you and your sales team. Maybe you need to perform text or sentiment analysis on the contents of your messages. Or maybe you’re creating visualizations to better understand who’s emailing you. This east guide will show you how you can use Data Pipeline to search and read emails from Gmail or G Suite, process them any way you like, and store them in Excel.

Updated: July 2021
Most examples of creating a Spring Batch ETL Job require an enormous amount of code for such a routine task. In this blog, I will show you how to accomplish the same task of summarizing a million stock trades to find the open, close, high, and low prices for each symbol using our Data Pipeline framework.

Updated: May 2023
When trying to assess how knowledgeable a developer is in general and in JDBC in particular, here’s a question I like to ask: how would you speed up inserts when using JDBC?
Here are some options to consider if you ever need to insert data quickly into an SQL database.

One feature of Data Pipeline is its ability to aggregate data without a database. This feature allows you to apply SQL “group by” operations to JSON, CSV, XML, Java beans, and other formats on-the-fly — in real-time. This quick tutorial will show you how to use the GroupByReader class to aggregate Twitter search results.

Data Pipeline now includes a new AsyncMultiReader endpoint that lets you read from multiple DataReaders in parallel. Here’s how it works.
Data Pipeline lets you read, write, and convert Excel files using a very simple API. This post will show you how to create Excel files containing more than one work sheet or tab.