
Updated: May 2023
With data being produced from many sources in a variety of formats businesses must have a sane way to gain useful insight. Data integration is the process of transforming data from one or more sources into a form that can be loaded into a target system or used for analysis and business intelligence.
Data integration libraries take some programming burden from the shoulders of developers by abstracting data processing and transformation tasks and allowing the developer to focus on tasks that are directly related to the application logic.
1. Data Pipeline

Data Pipeline is a versatile ETL framework designed to facilitate seamless data loading, processing, and migration on the JVM. With a Java I/O classes-inspired API, it accommodates diverse data formats and structures. Its efficient single-piece-flow methodology minimizes overhead while ensuring scalability via multi-threading. This streamlined approach enables handling of extensive data volumes and supports both batch and streaming data processing within the same pipelines.
The tool integrates an intuitive interface that enables reading from and writing to various data stores such as CSV, Excel, JSON, ORC, and Parquet, among others. It further extends its capabilities by incorporating data retrieval from platforms like Twitter, Gmail, Google Calendar, Amazon S3, MongoDB, and more.
Data Pipeline offers different versions tailored to different needs, ranging from the free Express edition to the robust Enterprise edition.
2. Spring Batch
Spring Batch is a framework designed for the development of batch applications commonly found in enterprise systems.
This lightweight framework caters to a wide range of job complexities, making it suitable for both simple and intricate tasks. It offers an array of features and services, including reusable functions for processing large records, logging and tracing capabilities, transaction management, job processing statistics, job restart functionality, skip options, and resource management. Additionally, optimization and partitioning techniques are employed to enhance performance and handle high-volume batch jobs efficiently.
While Spring Batch may have a learning curve, numerous resources such as books, videos, and tutorial blogs are readily available to assist users in harnessing the tool’s potential effectively.
3. Scriptella
Scriptella is a Java-based open-source tool for ETL (Extract, Transform, Load) and script execution. It proves valuable for tasks like database migration, database creation/update, cross-database ETL operations, and more.
One of Scriptella’s standout qualities is its simplicity. Users can leverage familiar languages like SQL to execute a wide range of transformations. The tool ensures interoperability by providing support for multiple data sources, including LDAP, JDBC, and XML. Furthermore, Scriptella seamlessly integrates with Ant, Java EE, Spring Framework, JMX, JNDI, and enterprise-ready scripts.
In summary, Scriptella offers an accessible and powerful solution for ETL and script execution in Java. Its simplicity, compatibility with various data sources, and integration capabilities make it a versatile tool for database operations and data transformations.
4. Easy Batch
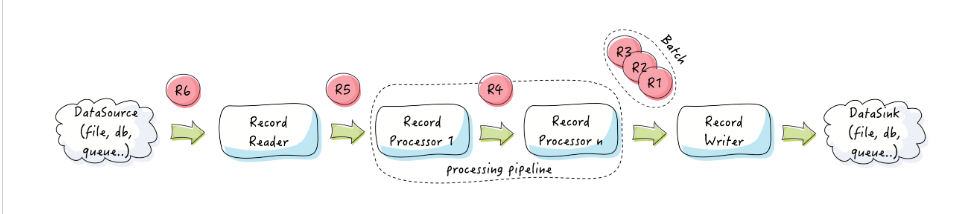
Easy Batch was specifically designed to eliminate the need for repetitive code involved in configuring data reading, writing, filtering, parsing, validation, logging, and reporting. By leveraging Easy Batch, users can direct their attention to application logic without being burdened by these routine tasks.
Using Easy Batch is straightforward. Records are sourced from a data repository, undergo processing within the pipeline, and are then written in batches to a designated data destination. The framework offers Record and Batch APIs, enabling the processing of records from various data sources, irrespective of their format or structure. With these features, Easy Batch simplifies the data processing workflow and allows users to focus on core application development.
5. GETL
GETL is a collection of libraries designed to streamline the data loading and transformation process.
Built on the foundation of Groovy, GETL comprises ready-to-use classes and objects that facilitate unpacking, transforming, and loading data into Java or Groovy applications. Furthermore, it seamlessly integrates with any software that operates with Java classes.
GETL offers support for diverse data sources, encompassing CSV, Excel, JSON, XML, Yaml, and DBF. Additionally, it empowers users to work with cloud-based sources like Kafka, enabling the reading and storage of records into datasets.
In summary, GETL simplifies data handling tasks by providing convenient libraries that automate loading and transformation. With compatibility across Java and Groovy programs, as well as support for various data formats and cloud sources, GETL enhances data processing efficiency.
6. Apache Camel

Apache Camel is a Java-based enterprise integration framework that can be seamlessly incorporated into Java applications, requiring minimal dependencies.
One of its key features is the utilization of domain-specific languages (DSL) for defining routing and mediation rules. While Apache Camel supports various DSLs like Spring, Scala DSL, and Blueprint XML, it is advisable to employ the Java-based Fluent API for rule definition. The framework employs URIs to interact with transport or messaging models such as HTTP, ActiveMQ, JMS, JBI, SCA, MINA, or CXF.
Apache Camel readily integrates with other frameworks like CDI, Spring, Blueprint, and Guice, ensuring compatibility and flexibility. Additionally, it offers support for bean binding and facilitates unit testing, enhancing the development and testing process. With its extensive capabilities, Apache Camel simplifies enterprise integration tasks in Java applications.
7. Apache Samza
Apache Samza is a robust and real-time data processing framework with built-in fault tolerance. It offers versatile deployment choices, enabling execution on YARN, Kubernetes, or as a standalone library.
The framework effortlessly handles diverse data sources, including Kafka, HDFS, and more. It boasts a straightforward API that accommodates both batch and streaming data, facilitating the creation of business logic within applications. Samza functions as a library and seamlessly integrates into Java and Scala applications.
Samza incorporates beneficial features like host-affinity and incremental check-pointing, ensuring swift recovery from failures and enhancing overall reliability. These capabilities contribute to a resilient and efficient data processing environment.
In summary, Apache Samza empowers developers with a flexible and fault-tolerant platform for real-time data processing, supporting various deployment options and offering seamless integration with Java and Scala applications.
8. Apache Flink
Apache Flink is a distributed processing engine and framework capable of performing stateful computations on both bounded and unbounded data streams. Developed using Java and Scala, Flink can seamlessly operate on any JVM setup, including support for Python and SQL.
A notable feature of Flink is its versatile deployment options, as it can be utilized in various cluster environments like YARN, Mesos, and Kubernetes. The framework offers connectors for data sources and sinks, facilitating seamless integration with storage systems such as Cassandra, Kafka, HDFS, and more. With its ability to execute computations at in-memory speed, Flink delivers high-performance processing capabilities while ensuring scalability to handle demanding workloads.
In summary, Apache Flink is a powerful distributed processing engine that excels in performing stateful computations on both bounded and unbounded data streams. Its broad language support, flexible deployment options, and integration with popular storage systems make it a robust choice for data processing tasks.
9. Apache Storm
Apache Storm is a real-time stream processing system that operates on Java and can seamlessly run on any JVM setup. In addition to Java, it also supports languages like Python, Ruby, and Perl.
Key features of this tool include its ability to deliver low-latency processing, straightforward setup process, user-friendly interface, support for parallel processing, cluster deployability, and extensive language support for forming topologies.
Storm finds utility in various applications such as ETL, RPC, real-time analytics, continuous computation, and more, effectively simplifying data processing tasks. It offers seamless integration with a wide range of queueing systems, including JMS, Kafka, Kestrel, and others, providing flexibility in data handling.
In summary, Apache Storm is a powerful real-time stream processing system that supports multiple programming languages, provides low-latency processing, and offers easy setup and parallel processing capabilities. Its versatility and compatibility with various queueing systems make it a valuable tool for a range of data processing tasks.
10. Apache Spark

Apache Spark is a unified analytics engine that supports multiple programming languages, allowing for batch and real-time streaming data processing. Built on Scala, it seamlessly runs on any JVM setup, offering compatibility with Java, SQL, Python, and R.
The core capabilities of Spark encompass batch and stream processing, SQL analytics, data science, and machine learning. It excels in big data analysis and machine learning tasks due to its efficiency and high-speed processing capabilities, even with extensive datasets.
Spark provides extensive support for diverse data stores and infrastructures, including Parquet, ORC, Kafka, MongoDB, and more. This flexibility enables seamless integration with various data sources, enhancing its versatility for data processing.
In summary, Apache Spark is a powerful analytics engine that supports multiple languages, offers efficient batch and stream processing, and serves as a valuable tool for big data analysis and machine learning. Its compatibility with various data stores and infrastructures further contributes to its broad utility in data processing workflows.
11. Apache NiFi
Apache NiFi is an open-source ETL tool with a web-based interface. It allows for easy design, management, and monitoring of data flows. NiFi supports various data sources, offers drag-and-drop functionality, and provides processors for data integration. It ensures data traceability, governance, and security. NiFi is scalable and fault-tolerant, making it suitable for handling large volumes of data. Overall, it simplifies and accelerates data integration processes.