We recently received an email from a Java developer asking how to convert records in a table (like you get in a relational database, CSV, or Excel file) to a composite tree structure. Normally, we’d point to one of Data Pipeline’s XML or JSON data writers, but for good reasons those options didn’t apply here. The developer emailing us needed the hierarchical structures in object form for use in his API calls.
Since we didn’t have a general purpose, table-tree mapper, we built one. We looked at several options, but ultimately decided to add a new operator to the GroupByReader. This not only answered the immediate mapping question, but also allowed him to use the new operator with sliding window aggregation if the need ever arose.
The rest of this blog will walk you through the implementation in case you ever need to add your own custom aggregate operator to Data Pipeline.
First let’s look at what this operator does.
Input CSV File
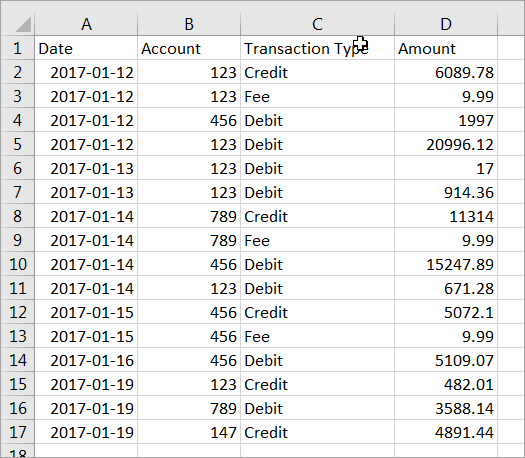
Let’s say you have the following CSV file. It’s pretty straightforward: it has a transaction date, the account it applies to, the type of transaction, and the amount applied.
Output Composite Structure
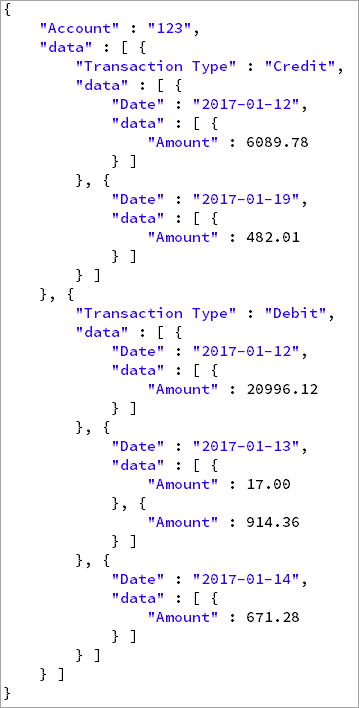
The goal is to take the input file and create a separate record for each account (123, 456, 789, and 147). Each of the new account records will contain nested records for the different transaction types, dates, and amounts related to that account. If the first record were converted to JSON, it would look structurally like the following.
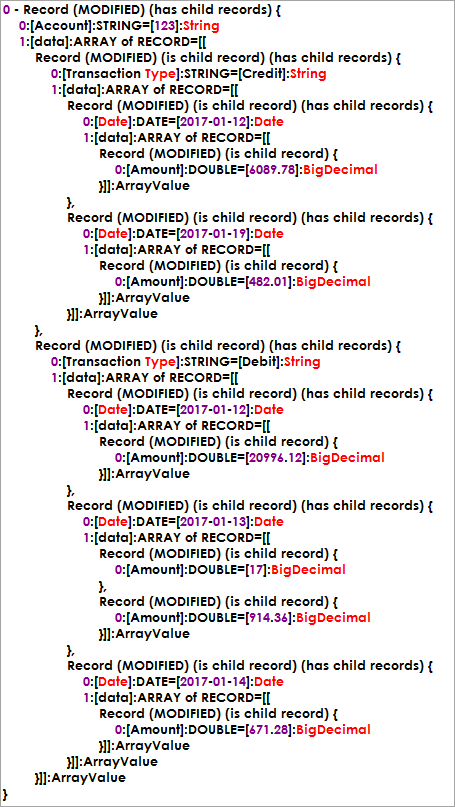
Since we’re not creating JSON, the actual Data Pipeline records will look very similar to JSON, but will contain rich types like BigDecimal and Date that JSON hasn’t traditionally supported. Here’s the output of Recors.toString().
The Data Pipeline Job
The work to read the CSV file, filter, transform, and aggregate it is seven steps.
1. Read the CSV file.
|
1 2 3 |
DataReader reader = new CSVReader(new File("financial-transactions.csv")) .setFieldNamesInFirstRow(true) .setSkipEmptyRows(true); |
2. Filter credit and debit transactions.
|
1 2 |
reader = new FilteringReader(reader) .add(new FieldFilter("Transaction Type").valueMatches("Credit", "Debit")); |
3. Select and arrange the output fields.
|
1 2 |
reader = new TransformingReader(reader) .add(new SelectFields("Account", "Transaction Type", "Date", "Amount")) |
4. Convert the fields from strings to their actual types
|
1 2 |
.add(new BasicFieldTransformer("Date").stringToDate("yyyy-MM-dd")) .add(new BasicFieldTransformer("Amount").stringToBigDecimal()) |
5. Sort the data to ensure child branches are grouped together.
|
1 |
reader = new SortingReader(reader).asc("Account").asc("Transaction Type").asc("Date").asc("Amount"); |
6. Use the new GroupTree aggregate operator – that we’ll implement below – to build the new records grouped-by account as the root of each branch.
|
1 |
reader = new GroupByReader(reader, "Account").add(new GroupTree("data")); |
7. Write to the desired target.
|
1 2 |
DataWriter writer = StreamWriter.newSystemOutWriter(); Job.run(reader, writer); |
This example writes to the console (System.out), but the developer can implement his custom API calls as a new DataWriter subclass.
Data Pipeline Aggregation API
Before we get into the GroupTree implementation, you need to understand the classes involved in aggregation and sliding windows.
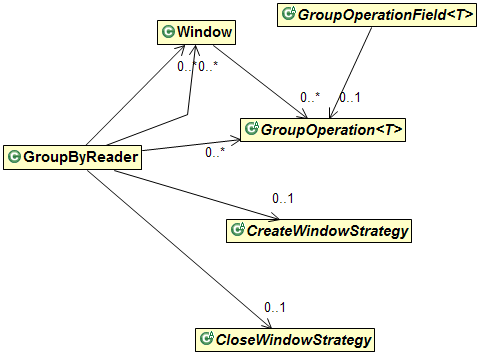
GroupByReader
GroupByReader is the controlling class and is what we used in the example above. GroupByReader holds a list of open windows and closed windows (while they still have data to emit). It also holds the GroupOperations that will be applied in each window along with the window strategies.
Window Strategies
The CreateWindowStrategy classes is responsible for determining when new windows should be opened, while CloseWindowStrategy determines when open windows should be closed. There are several built-in implementations based on time and data. You can implement your own strategies or combine strategies together using Boolean logic.
Windows
Windows receive incoming data while they’re open and emit their results after they’re closed. Open windows take the input records and apply GroupOperations (sum, count, etc.) to them via a GroupField instance. Once a window is closed, the values in its GroupFields are collected into records and returned by GroupByReader.
Operators
You can think of GroupOperation as a factory that creates GroupOperationFields. Whenever an open window determines that a new aggregate field needs to be created for a record in the output group, it calls GroupOperation.createField(). The window then calls GroupOperationField.apply(Record, Field) for each input record it sees. Most of the operator’s logic is actually done inside each implementation of the field’s apply() method.
GroupTree Implementation
First the code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
package com.northconcepts.datapipeline.group; import com.northconcepts.datapipeline.core.ArrayValue; import com.northconcepts.datapipeline.core.Field; import com.northconcepts.datapipeline.core.Record; import com.northconcepts.datapipeline.group.GroupOperation; import com.northconcepts.datapipeline.group.GroupOperationField; import com.northconcepts.datapipeline.internal.lang.Util; public class GroupTree extends GroupOperation<ArrayValue> { public GroupTree(String targetFieldName) { super(null, targetFieldName, false); } @Override protected GroupOperationField<ArrayValue> createField() { return new GroupOperationField<ArrayValue>(this) { private Record rootRecord = new Record(); @Override protected void apply(Record record, Field field) { Record parentDataRecord = rootRecord; FIELD_LOOP: for (int i = 1; i < record.getFieldCount(); i++) { Field sourceField = record.getField(i); ArrayValue dataArray = parentDataRecord.getField(getTargetFieldName(), true).getValueAsArray(true); if (dataArray.size() > 0) { Record lastDataRecord = dataArray.getValueAsRecord(dataArray.size() - 1); Field lastDataRecordField = lastDataRecord.getField(sourceField.getName(), true); boolean sameTreeBranch = Util.equals(lastDataRecordField.getValue(), sourceField.getValue()); if (sameTreeBranch) { parentDataRecord = lastDataRecord; continue FIELD_LOOP; } } Record lastDataRecord = new Record(); lastDataRecord.setField(sourceField.getName(), sourceField.getValue()); dataArray.addValue(lastDataRecord); parentDataRecord = lastDataRecord; } } @Override protected ArrayValue getValue() { return rootRecord.getField(0).getValueAsArray(); } }; } } |
GroupTree
The new operator starts by extending the GroupOperation class and overriding its createField() factory method. In our example, createField() will be called once for every new account and the resulting field’s apply() will be called once for every record related to that account. The apply() method will be responsible for adding each tabular record to the appropriate place in the nested tree record that it will eventually return. As an example, the simplest apply() method we have is in the GroupCount class and it just increments a counter.
Get Value
The created field’s getValue() method is called by closed windows whenever they are asked by GroupByReader for records. In this case, it will return the first field in the root record as an array.
Next Release
The GroupTree operator will be available in the next release. If you can’t wait, just use the code from this blog and get started.
Happy Coding!