Late December we released DataPipeline version 8.0.0 to general availability. This might be our longest list of new features and changes yet. Let’s dive in.
Late December we released DataPipeline version 8.0.0 to general availability. This might be our longest list of new features and changes yet. Let’s dive in.
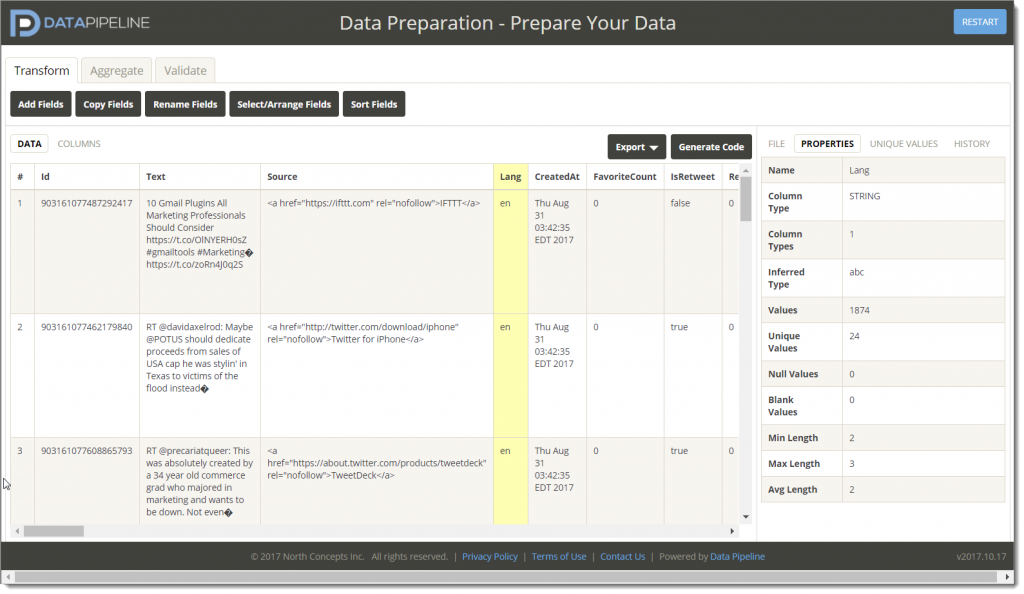
We’re building on a new tool to help you work faster with Data Pipeline.
This new tool is a web app that lets you interactively transform, filter, and prepare data on-the-fly. It also lets you generate Data Pipeline code based on the actions you perform.
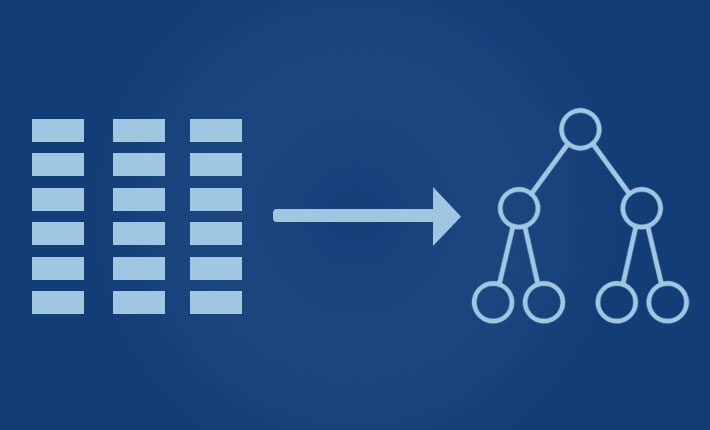
We recently received an email from a Java developer asking how to convert records in a table (like you get in a relational database, CSV, or Excel file) to a composite tree structure. Normally, we’d point to one of Data Pipeline’s XML or JSON data writers, but for good reasons those options didn’t apply here. The developer emailing us needed the hierarchical structures in object form for use in his API calls.
Since we didn’t have a general purpose, table-tree mapper, we built one. We looked at several options, but ultimately decided to add a new operator to the GroupByReader. This not only answered the immediate mapping question, but also allowed him to use the new operator with sliding window aggregation if the need ever arose.
The rest of this blog will walk you through the implementation in case you ever need to add your own custom aggregate operator to Data Pipeline.

Updated: May 2023
ETL is a process for performing data extraction, transformation and loading. The process extracts data from a variety of sources and formats, transforms it into a standard structure, and loads it into a database, file, web service, or other system for analysis, visualization, machine learning, etc.
ETL tools come in a wide variety of shapes. Some run on your desktop or on-premises servers, while others run as SaaS in the cloud. Some are code-based, built on standard programming languages that many developers already know. Others are built on a custom DSL (domain specific language) in an attempt to be more intentional and require less code. Others still are completely graphical, only offering programming interfaces for complex transformations.
What follows is a list of ETL tools for developers already familiar with Java and the JVM (Java Virtual Machine) to clean, validate, filter, and prepare your data for use.