Data Pipeline makes it easy to read, transform, and write XML and Excel files. This post shows you how you too can load data from an on-disk XML file, apply transformations on the fly, and save the result to an Excel file.
If you need to read data directly from a URL and skip the disk altogether, take a look at the How to Read a JSON Stream example. If you prefer to write your data to multiple Excel sheets, you can read the post How to create multiple sheets in a single Excel file.
Input XML file
For this example, we will process stock quotes available at Yahoo Finance. We saved this XML data on disk in a file named “yahoo_stock_quote_feed.xml”.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<?xml version="1.0" encoding="UTF-8"?> <query xmlns:yahoo="http://www.yahooapis.com/v1/base.rng" yahoo:count="4" yahoo:created="2015-06-19T10:01:24Z" yahoo:lang="en-US"> <results> <quote symbol="YHOO"> <Ask>41.26</Ask> <AverageDailyVolume>14324400</AverageDailyVolume> <Bid>40.66</Bid><AskRealtime/><BidRealtime/> <BookValue>35.91</BookValue> <Change_PercentChange>-0.05 - -0.12%</Change_PercentChange> <Change>-0.05</Change> <Commission/> <Currency>USD</Currency> |
Java code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
package com.northconcepts.datapipeline.examples.cookbook.blog; import java.io.File; import com.northconcepts.datapipeline.core.DataReader; import com.northconcepts.datapipeline.core.DataWriter; import com.northconcepts.datapipeline.core.FieldType; import com.northconcepts.datapipeline.excel.ExcelDocument; import com.northconcepts.datapipeline.excel.ExcelWriter; import com.northconcepts.datapipeline.job.JobTemplate; import com.northconcepts.datapipeline.transform.BasicFieldTransformer; import com.northconcepts.datapipeline.transform.MoveFieldBefore; import com.northconcepts.datapipeline.transform.RemoveFields; import com.northconcepts.datapipeline.transform.SetCalculatedField; import com.northconcepts.datapipeline.transform.TransformingReader; import com.northconcepts.datapipeline.xml.XmlReader; public class ConvertAnXmlFileToAnExcelFile { public static void main(String[] args) { /* * 1) Define a reader from an XML file */ DataReader xmlReader = new XmlReader(new File("example/data/input/yahoo_stock_quote_feed.xml")) .addField("company", "//quote/Name") .addField("ticker", "//quote/@symbol") .addField("EBITDA", "//quote/EBITDA") .addField("last trade date", "//quote/LastTradeDate") .addField("currency", "//quote/Currency") .addField("ask", "//quote/Ask") .addField("bid", "//quote/Bid") .addField("day range", "//quote/DaysRange") .addRecordBreak("//quote"); /* * 2) Transform the input data on-the-fly (optional) */ DataReader transformingReader = new TransformingReader(xmlReader) .add( new BasicFieldTransformer("EBITDA") .replaceAll("M", "E6") .replaceAll("B", "E9") .stringToDouble() .numberToInt(), new BasicFieldTransformer("last trade date") .stringToDate("M/d/y"), new BasicFieldTransformer("bid") .stringToDouble(), new BasicFieldTransformer("ask") .stringToDouble(), new SetCalculatedField("bid-ask spread", "bid-ask"), new RemoveFields("ask"), new MoveFieldBefore("bid-ask spread", "day range"), new BasicFieldTransformer("day range") .replaceAll(" - ", ", ") .prepend("[") .append("]") ); /* * 3) Define a writer to an Excel file */ ExcelDocument excelDocument = new ExcelDocument(); //default is .xlsx format (Excel 2007+) DataWriter excelWriter = new ExcelWriter(excelDocument) .setSheetName("stocks") .setAutofitColumns(true) .setStyleFormat(FieldType.INT, "0.00E+00") .setStyleFormat(FieldType.DOUBLE, "0.00") .setStyleFormat(FieldType.DATE, "yyyy-mmm-dd, ddd"); /* * 4) Transfer the data from the XML file to the Excel file and save the result */ JobTemplate.DEFAULT.transfer(transformingReader, excelWriter); excelDocument.save(new File("example/data/output/stock_quote_summary.xlsx")); } } |
1. Define a reader from an XML file
XmlReader lets you get records from an XML stream. The XML stream is broken into separate records by calling addRecordBreak(String locationPath) on your XmlReader instance. Fields are then added to each record using the addField(String name, String locationPath) method. The locationPath expressions used in the above methods are a subset of the XPath 1.0 location paths notation. Below we give an example of location paths for selecting a node and an attribute:
"//quote/Company"– selects all Company nodes that are children of a quote node no matter where they are in the document;"//quote/@symbol"– selects the symbol attribute in all quote nodes no matter where they are in a document.
2. Transform the input data on the fly (optional)
When converting data between formats, we often need to perform transformations. For example, we may read numbers as text from an XML file, but prefer to save them as a number in an Excel file. Or, we may need to adjust the date and number formatting, and calculate aggregated values.
TransformingReader is a proxy that applies transformations to records being passed through it. Record transformations are then added to a TransformingReader using the method add(Transformer... transformers). Data Pipeline makes it easy to:
- transform field values: BasicFieldTransformer;
- add calculated and constant value fields: SetCalculatedField, SetField;
- modify the field list: SelectFields, MoveFieldAfter, MoveFieldBefore, RemoveFields, CopyField, RenameField;
- split array fields and lookup data: SplitArrayField, LookupTransformer.
The following posts contain additional on-the-fly data-transformation examples: Lookup Data in any Data Reader, Search Twitter for Tweets, Rename a Field and Set a Field.
3. Define a writer to a Microsoft Excel file
ExcelWriter lets you write records to a Microsoft Excel document. We use it in combination with ExcelDocument, a class that encapsulates an Excel workbook in memory. Data Pipeline supports both the XLS and XSLX file format. By default, the ExcelDocument objects represent an XLSX file. You can use ExcelWriter’s setStyleFormat(FieldType fieldType, String pattern) method to set the desired cell format per data type.
4. Transfer the data from the XML file to the Excel file and save the result
JobTemplate is a base type for classes that transfer records from a DataReader to a DataWriter. Data Pipeline provides a default JobTemplate implementation which you can access at JobTemplate.DEFAULT. A call to the method JobTemplate.DEFAULT.transfer(DataReader reader, DataWriter writer) is responsible for doing the data transfer.
Finally, a call to the ExcelDocument’s save(File excelFile) method is needed to write the generated workbook data to an Excel file on disk.
Output file
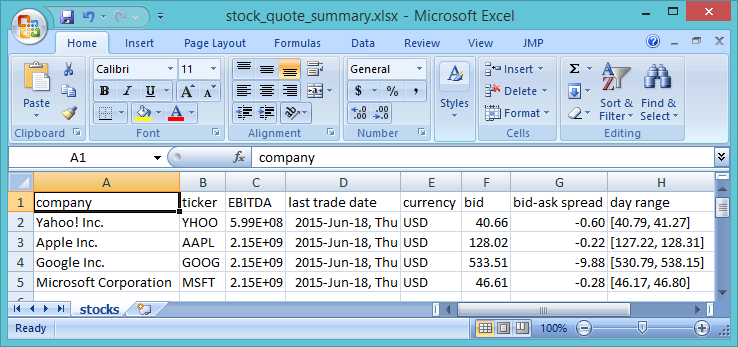
All examples can be found in the examples/src folder of the download.
Pingback: How to convert XML to Excel | Dinesh Ram Kali.
Pingback: Data Pipeline 3.1 Now Available - Data Pipeline