One feature of Data Pipeline is its ability to aggregate data without a database. This feature allows you to apply SQL “group by” operations to JSON, CSV, XML, Java beans, and other formats on-the-fly — in real-time. This quick tutorial will show you how to use the GroupByReader class to aggregate Twitter search results.


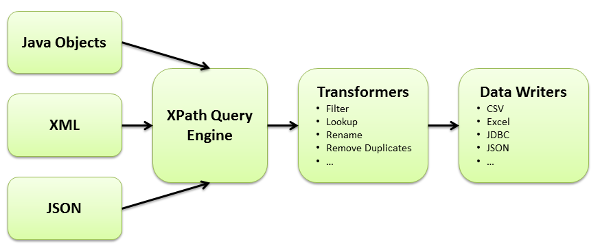
 This blog will demonstrate how to upload Excel and CSV files into a database while using Data Pipeline to handle the differences in format and structure of the individual files.
This blog will demonstrate how to upload Excel and CSV files into a database while using Data Pipeline to handle the differences in format and structure of the individual files.