Updated: May 2023
ETL is a process for performing data extraction, transformation and loading. The process extracts data from a variety of sources and formats, transforms it into a standard structure, and loads it into a database, file, web service, or other system for analysis, visualization, machine learning, etc.
ETL tools come in a wide variety of shapes. Some run on your desktop or on-premises servers, while others run as SaaS in the cloud. Some are code-based, built on standard programming languages that many developers already know. Others are built on a custom DSL (domain specific language) in an attempt to be more intentional and require less code. Others still are completely graphical, only offering programming interfaces for complex transformations.
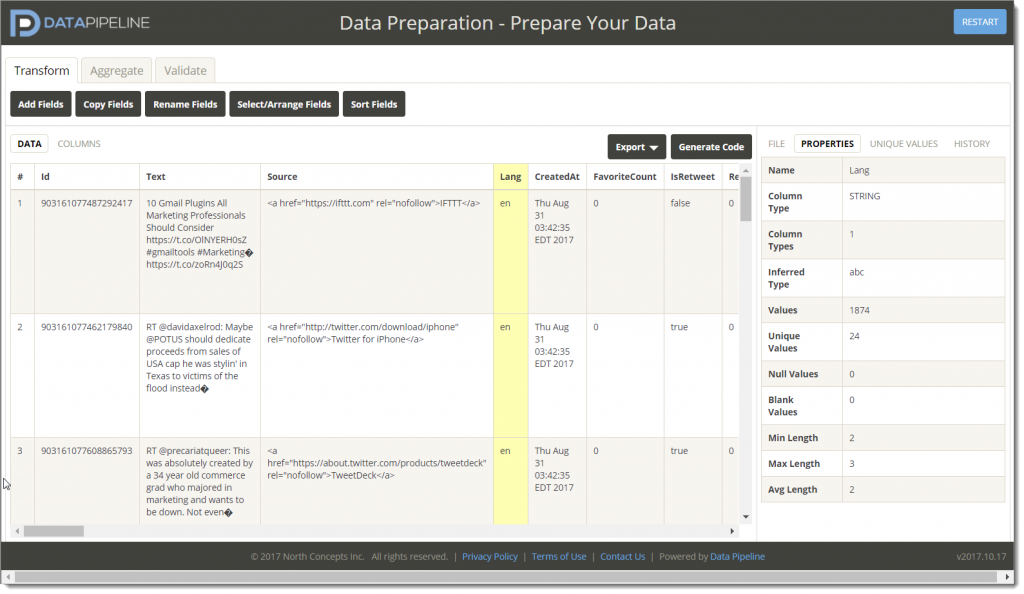
What follows is a list of ETL tools for developers already familiar with Java and the JVM (Java Virtual Machine) to clean, validate, filter, and prepare your data for use.
Continue reading →