
We’re pleased to announce the release of DataPipeline version 6.0. This release includes our new DataPipeline Foundations addon that brings decisioning, source-target data mapping, and other cool features to your software.
We’re pleased to announce the release of DataPipeline version 6.0. This release includes our new DataPipeline Foundations addon that brings decisioning, source-target data mapping, and other cool features to your software.

Updated: May 2023
With data being produced from many sources in a variety of formats businesses must have a sane way to gain useful insight. Data integration is the process of transforming data from one or more sources into a form that can be loaded into a target system or used for analysis and business intelligence.
Data integration libraries take some programming burden from the shoulders of developers by abstracting data processing and transformation tasks and allowing the developer to focus on tasks that are directly related to the application logic.

Today we’re pleased announce the release of Data Pipeline version 4.4. This update includes integration with Amazon S3, new features to better handle real-time data and aggregation, and new XML and JSON readers to speed up your development.
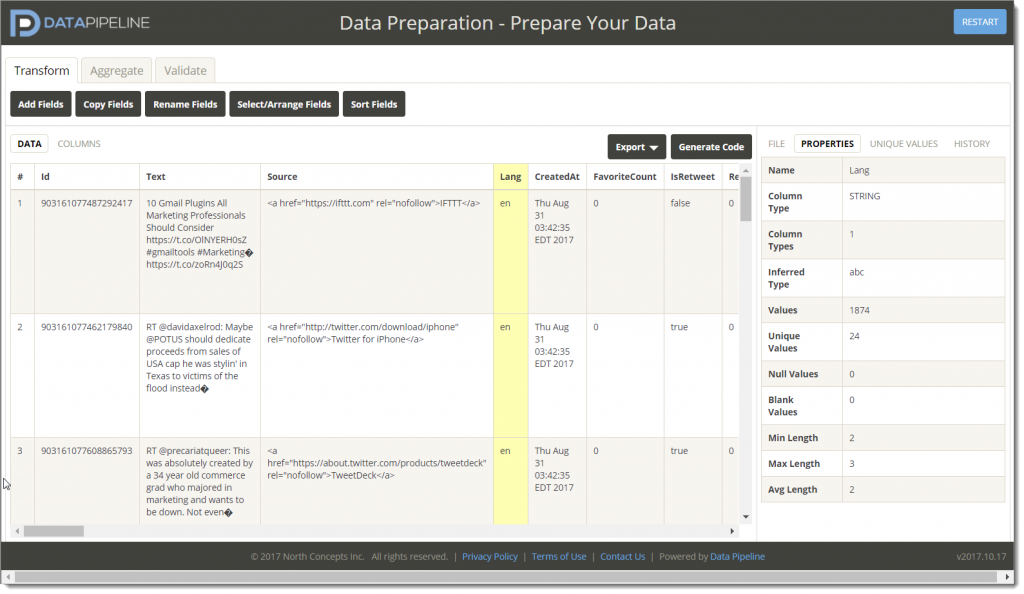
We’re building on a new tool to help you work faster with Data Pipeline.
This new tool is a web app that lets you interactively transform, filter, and prepare data on-the-fly. It also lets you generate Data Pipeline code based on the actions you perform.
We’re excited to introduce Data Pipeline version 4.1, the second update on our 2016 roadmap.
This release features MongoDB integration, expression language additions, and improved transformations and joins. We’ve also thrown in a ton of examples for all the new 4.1 and 4.0 features. Enjoy. Continue reading
Data Pipeline v3.1.4 is now available for download. This release includes support for MySQL upserts, lower JSON and XML memory usage, bug fixes, and more.
Continue reading
Data Pipeline 3.1 is now available for download. This is a milestone release that adds native support for hierarchical data (nested records and multidimensional arrays).
Data Pipeline makes it easy to read, transform, and write XML and Excel files. This post shows you how you too can load data from an on-disk XML file, apply transformations on the fly, and save the result to an Excel file.
Data Pipeline lets you read, write, and convert Excel files using a very simple API. This post will show you how to create Excel files containing more than one work sheet or tab.
We’re pleased to announce the release of version 3.0 of our Data Pipeline engine.
This release includes the new Sliding Window Aggregations feature to perform continuous SQL group-by operations on streaming data.
We’ve improved the performance of the XPath based readers (JsonReader, XmlReader, and JavaBeanReader), included new conveniences to reduce your code size, and added several new transformers and filters.
We’re also now offering a free 30-day trial for you to take the premium and enterprise features out for a test drive.